iForest (Isolation Forest)是由Liu et al. [1] 提出来的基于二叉树的ensemble异常检测算法,具有效果好、训练快(线性复杂度)等特点。
1. 前言
iForest为聚类算法,不需要标记数据训练。首先给出几个定义:
- 划分(partition)指样本空间一分为二,相当于决策树中节点分裂;
- isolation指将某个样本点与其他样本点区分开。
iForest的基本思想非常简单:完成异常点的isolation所需的划分数大于正常样本点(非异常)。如下图所示:
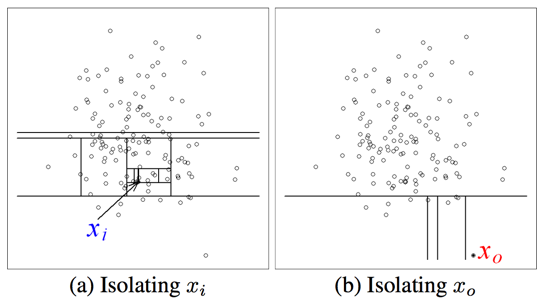
\(x_i\)样本点的isolation需要大概12次划分,而异常点\(x_0\)指需要4次左右。因此,我们可以根据划分次数来区分是否为异常点。但是,如何建模呢?我们容易想到:划分对应于决策树中节点分裂,那么划分次数即为从决策树的根节点到叶子节点所经历的边数,称之为路径长度(path length)。假设样本集合共有\(n\)个样本点,对于二叉查找树(Binary Search Tree, BST),则查找失败的平均路径长度为
\[ c(n) = 2H(n-1) -(2(n-1)/n) \] 其中,\(H(i)\)为harmonic number,可估计为\(\ln (i) + 0.5772156649\)。那么,可建模anomaly score:\[ s(x,n) = 2^{-\frac{E(h(x))}{c(n)}} \]
其中,\(h(x)\)为样本点\(x\)的路径长度,\(E(h(x))\)为iForest的多棵树中样本点\(x\)的路径长度的期望。特别地,

当\(s\)值越高(接近于1),则表明该点越可能为异常点。若所有的样本点的\(s\)值都在0.5左右,则说明该样本集合没有异常点。
2. 详解
iForest采用二叉决策树来划分样本空间,每一次划分都是随机选取一个属性值来做,具体流程如下:

停止分裂条件:
- 树达到了最大高度;
- 落在孩子节点的样本数只有一个,或者所有样本点的值均相同;
为了避免错检(swamping)与漏检(masking),在训练每棵树的时候,为了更好地区分,不会拿全量样本,而会sub-sampling样本集合。iForest的训练流程如下:

给出了iForest与其他异常检测算法的比较。
3. 参考资料
[1] Liu, Fei Tony, Kai Ming Ting, and Zhi-Hua Zhou. "Isolation forest." Data Mining, 2008. ICDM'08. Eighth IEEE International Conference on. IEEE, 2008.